elasticsearch安装使用
0x1 前置
因为最近有需求上10G的数据查询, 并且需要模糊查询, 尝试使用mysql, 结果需要快10分钟, 这个真的接受不了, 经过一番了解, 决定使用elasticsearch
0x2 什么是Elasticsearch
Elasticsearch 是一款稳定高效的分布式搜索和分析引擎,它的底层基于 Lucene,并提供了友好的 RESTful API 来对数据进行操作,还有比较重要的一点是, Elasticsearch 开箱即可用,上手也比较容易。
目前 Elasticsearch 在搭建企业级搜索(如日志搜索、商品搜索等)平台中很广泛,官网也提供了不少案例,比如:
GitHub 使用 Elasticsearch 检索超过 800 万的代码库
eBay 使用 Elasticsearch 搜索海量的商品数据
Netflix 使用 Elasticsearch 来实现高效的消息传递系统
0x3 安装
1.Elasticsearch依赖JAVA, 需要安装JDK, 这里我就不赘述了;
2.下载elasticsearch, 下载对应系统的安装包就好
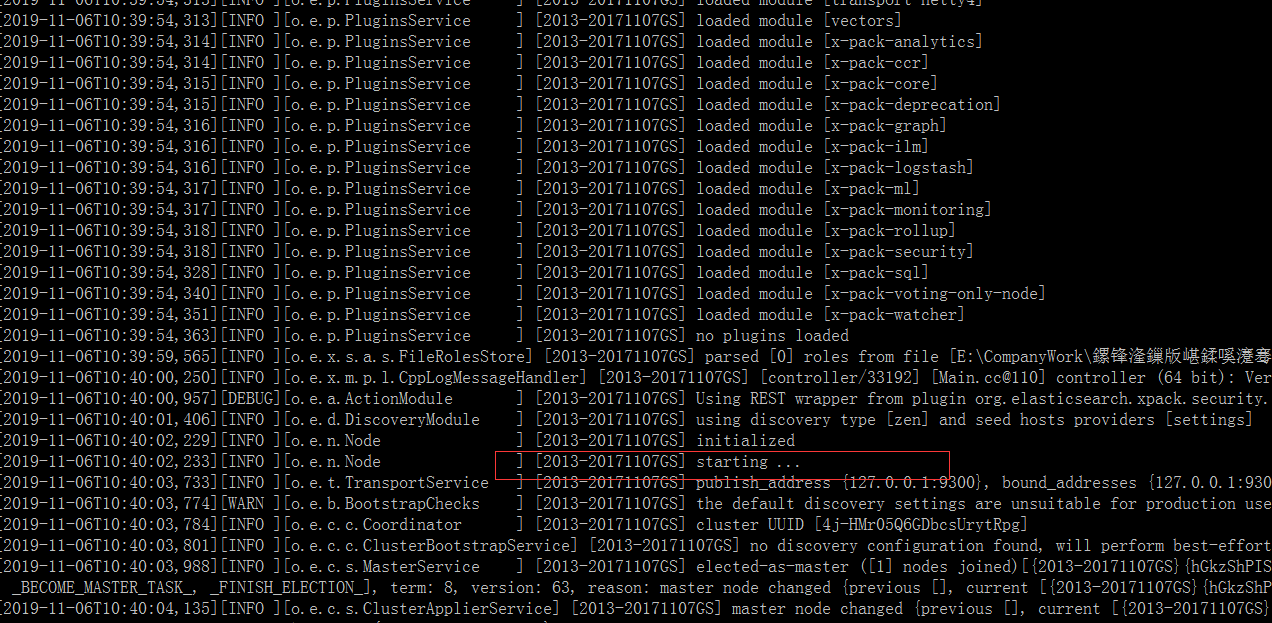
3.下载zip包后解压, 进入bin目录打开命令行窗口,运行命令“elasticsearch”, 可以看到启动的日志
Elasticsearch 启动后,也启动了两个端口 9200 和 9300:
- 9200 端口:HTTP RESTful 接口的通讯端口
- 9300 端口:TCP 通讯端口,用于集群间节点通信和与 Java 客户端通信的端口
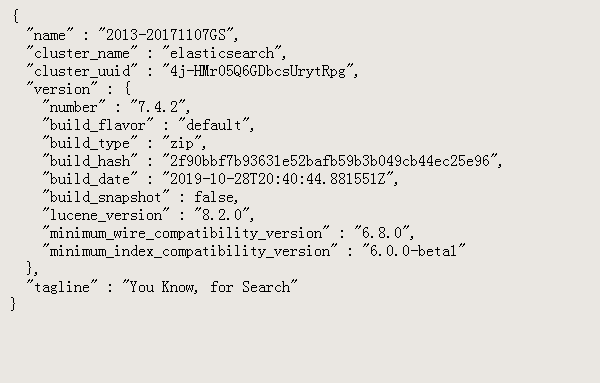
4.运行完之后不要关闭窗口,在浏览器里访问127.0.0.1:9200,看到以下内容说明Elasticsearch安装成功了
0x4 概念
elasticsearch储存和mysql储存字段的区别
| Elasticsearch | MySQL |
|---|---|
| Index | Database |
| Type | Table |
| Document | Row |
| Field | Column |
- Index (索引):这里的 Index 是名词,一个 Index 就像是传统关系数据库的 Database,它是 Elasticsearch 用来存储数据的逻辑区域
- Document (文档):Elasticsearch 使用 JSON 文档来表示一个对象,就像是关系数据库中一个 Table 中的一行数据
- Type (类型):文档归属于一种 Type,就像是关系数据库中的一个 Table
- Field (字段):每个文档包含多个字段,类似关系数据库中一个 Table 的列
在物理层面:
- Node (节点):node 是一个运行着的 Elasticsearch 实例,一个 node 就是一个单独的 server
- Cluster (集群):cluster 是多个 node 的集合
- Shard (分片):数据分片,一个 index 可能会存在于多个 shard
因为我是在本机搭建, 所以就没有关注物理层的点…
0x5 Python操作Elasticsearch
1 | # -.- coding:utf-8 -.- |
0x6 插入查询注意点
1.bulk插入大量的数据, 经过测试每次10W最优
2.模糊查询亿级数据, 可以秒出数据
3.插入后的数据大概会膨胀4倍, 所以需要预留好空间
4.需要插入的文本数据太大不好操作, 最好做分割
1 | #文本分割 |
0x7 Elasticsearch可视化工具
1.elasticsearch-head
2.ElasticHD(我用的这个)
3.Dejavu
常用的有三款可视化工具, 我这里使用的ElasticHD
进入release, 下载对应系统的二进制文件, 执行命令就可以连接
1 | ./ElasticHD -p 127.0.0.1:9800 |
不出意外, 就会跳出该页面, 使用127.0.0.1:9800也可以访问
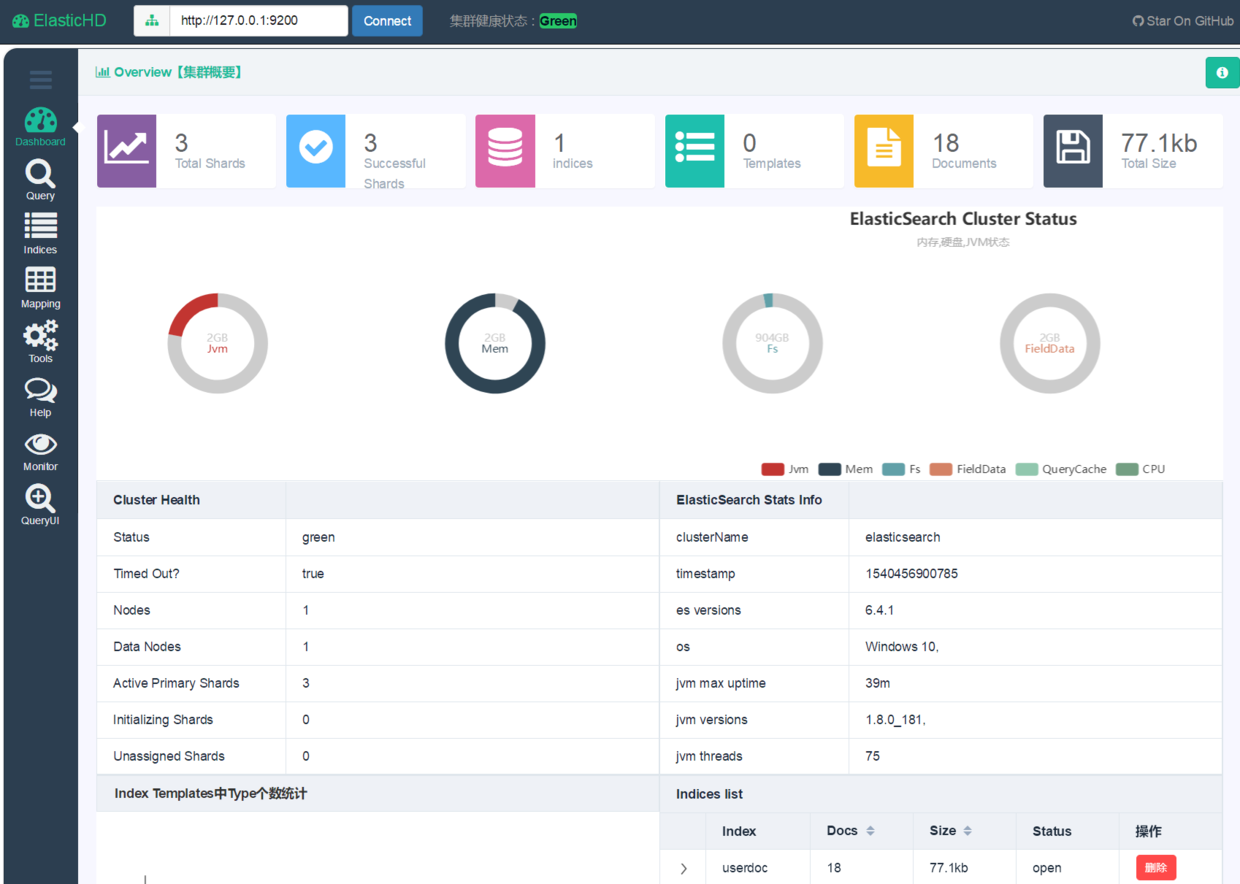
但是查询会有个问题, 并且运行中elasticsearch会抛异常, 这个问题还没确定, 我暂时还使用的python查询